
Industry news
openGauss查询优化——optimizer
优化器(optimizer)的任务是创建最佳执行计划。一个给定的SQL查询以及一个查询树实际上可以以多种不同的方式执行,每种方式都会产生相同的结果集。如果在计算上可行,则查询优化器将检查这些可能的执行计划中的每一个,最终选择预期运行速度最快的执行计划。在某些情况下,检查执行查询的每种可能方式都会占用大量时间和内存空间,特别是在执行涉及大量连接操作(join)的查询时。为了在合理的时间内确定合理的(不一定是最佳的)查询计划,当查询连接数超过阈值时,openGauss使用遗传查询优化器(genetic query optimizer),通过遗传算法来做执行计划的枚举。
优化器的查询计划(plan)搜索过程实际上与称为路径(path)的数据结构一起使用,该路径只是计划的简化表示,其中仅包含确定计划所需的关键信息。确定代价最低的路径后,将构建完整的计划树以传递给执行器。这足够详细地表示了所需的执行计划,供执行者运行。在本节的其余部分,将忽略路径和计划之间的区别。
1) 生成查询计划
首先,优化器会生成查询中使用的每个单独关系(表)的计划。候选计划由每个关系上的可用索引确定。对关系的顺序扫描是查询最基本的方法,因此总是会创建顺序扫描计划。假设在关系上定义了索引(例如B树索引),并且查询属性恰好与B树索引的键匹配,则使用B树索引创建另一个基于索引的查询计划。如果还存在其他索引并且查询中的限制恰好与索引的关键字匹配,则将考虑其他计划生成更多计划。
其次,如果查询需要连接两个或多个关系,则在找到所有可行的扫描单个关系的计划之后,将考虑连接关系的计划。连接关系有3种可用的连接策略:
(1) 嵌套循环连接:对在左关系中找到的每一行,都会扫描一次右关系。此策略易于实施,但非常耗时。(但是如果可以使用索引扫描来扫描右关系,这可能是一个不错的策略。可以将左关系的当前行中的值用作右索引扫描的键。)
(2)合并连接:在开始连接之前,对进行连接的每个关系的连接属性进行排序。然后,并行扫描进行连接的这两个关系,并组合匹配的行以形成连接行。这种连接更具吸引力,因为每个关系只需扫描一次。所需的排序可以通过明确的排序步骤来实现,也可以通过使用连接键上的索引以正确的顺序扫描关系来实现。
(3) 哈希连接:首先将正确的关系扫描并使用其连接属性作为哈希键加载到哈希表(hash table,也叫散列表)中。接下来,扫描左关系,并将找到的每一行的适当值用作哈希键,以在表中找到匹配的行。
当查询涉及两个以上的关系时,最终结果必须由构建连接树来确定。优化器检查不同的可能连接顺序以找到代价最低的连接顺序。
如果查询所使用的关系数目较少(少于启动启发式搜索阈值),那么将进行近乎穷举的搜索以找到最佳连接顺序。优化器优先考虑存在WHERE限定条件子句中的两个关系之间的连接(即存在诸如rel1.attr1=rel2.attr2之类的限制),最后才考虑不具有join子句的连接对。优化器会对每个连接操作生成所有可能的执行计划,然后选择(估计)代价最低的那个。当连接表数目超过geqo_threshold时,所考虑的连接顺序由基因查询优化(Genetic Query Optimization,GEQO)启发式方法确定。
完成的计划树包括对基础关系的顺序或索引扫描,以及根据需要的嵌套循环、合并、哈希连接节点和其他辅助步骤,例如排序节点或聚合函数计算节点。这些计划节点类型中的大多数具有执行选择(丢弃不满足指定布尔条件的行)和投影(基于给定列值计算派生列集,即执行标量表达式的运算)的附加功能。优化器的职责之一是将WHERE子句中的选择条件附加起来,并将所需的输出表达式安排到计划树的最适当节点上。
2) 查询计划代价估计
openGauss的优化器是基于代价的优化器,对每条SQL语句生成的多个候选的计划,优化器会计算一个执行代价,最后选择代价最小的计划。
通过统计信息,代价估算系统就可以了解一个表有多少行数据、用了多少个数据页面、某个值出现的频率等,以确定约束条件过滤出的数据占总数据量的比例,即选择率。当一个约束条件确定了选择率之后,就可以确定每个计划路径所需要处理的行数,并根据行数可以推算出所需要处理的页面数。当计划路径处理页面的时候,会产生I/O代价。而当计划路径处理元组的时候(例如针对元组做表达式计算),会产生CPU代价。由于openGauss是单机数据库,无服务器节点间传输数据(元组)会产生通信的代价,因此一个计划的总体代价可以表示为:
总代价=I/O代价 + CPU代价
openGauss把所有顺序扫描一个页面的代价定义为单位1,所有其他算子的代价都归一化到这个单位1上。比如把随机扫描一个页面的代价定义为4,即认为随机扫描一个页面所需代价是顺序扫描一个页面所需代价的4倍。又比如,把CPU处理一条元组的代价为0.01,即认为CPU处理一条元组所需代价为顺序扫描一个页面所需代价的1/100。
从另一个角度来看,openGauss将代价又分成了启动代价和执行代价,其中:
总代价=启动代价 + 执行代价
(1) 启动代价。
从SQL语句开始执行到此算子输出第一条元组为止,所需要的代价称为启动代价。有的算子启动代价很小,比如基表上的扫描算子,一旦开始读取数据页,就可以输出元组,因此启动代价为0。有的算子的启动代价相对较大,比如排序算子,它需要把所有下层算子的输出全部读取到,并且把这些元组排序之后,才能输出第一条元组,因此它的启动代价比较大。
(2) 执行代价。
从输出第一条算子开始,至查询结束,所需要的代价,称为执行代价。这个代价中又可以包含CPU代价、I/O代价,执行代价的大小与算子需要处理的数据量有关,也与每个算子完成的功能有关。处理的数据量越大、算子需要完成的任务越重,则执行代价越大。
(3) 总代价。
如图1-4所示示例,查询中包含两张表,分别命名为t1、t2。t1与t2进行join操作,并且对c1列做聚集。
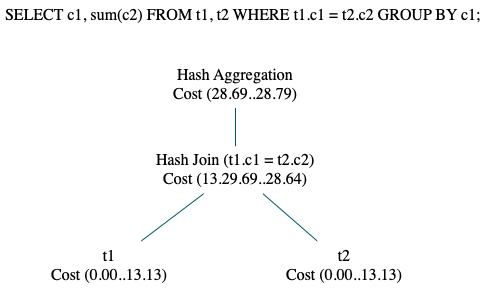
图1-4 代价计算示例
示例中涉及的代价包括:
(1) 扫描t1的启动代价为0,总代价为13.13。13.13的意思是“总代价相当于顺序扫描13.13个页面”,t2表的扫描同理。
(2) 此计划的join方式为hash join,使用hash join时,必须先对一个子节点的所有数据建立哈希表,再依次使用另一个子节点的每一条元组尝试与hash join中的元组进行匹配。因此hash join的启动代价包括了建立哈希表的代价。
此计划中hash join的启动代价为13.29,对某个结果集建立哈希表时,必须拿到此结果集的所有数据,因此13.29比下层扫描算子的代价13.13大。
此计划中hash join的总代价为28.64。
(3) join完毕之后,需要做聚集运算,此计划中的聚集运算使用了HashAGG算子,此算子需要对join的结果集以c1列作为hash Key建立哈希表,因此它的启动代价又包含了一个建立哈希表的代价。聚集操作的启动代价为28.69,总代价为28.79。
3) optimizer源码组织
optimizer源码目录为:/src/gausskernel/optimizer。optimizer源码文件如表1-7所示。
表1-7 optimizer源码文件
| 模块 | 源码文件 | 功能 |
| plan | analyzejoins.cpp | 初始化查询后的连接简化 |
| createplan.cpp | 创建查询计划 | |
| dynsmp_single.cpp | SMP自适应接口函数 | |
| planner.cpp | 查询优化外部接口 | |
| planrecursive_single.cpp | with_recursive递归查询的处理函数 | |
| planrewrite.cpp | 基于代价的查询重写 | |
| setrefs.cpp | 完成的查询计划树的后处理(修复子计划变量引用) | |
| initsplan.cpp | 目标列表、限定条件和连接信息初始化 | |
| pgxcplan_single.cpp | 简单查询的旁路执行器 | |
| planagg.cpp | 聚集查询的特殊计划 | |
| planmain.cpp | 计划主函数:单个查询的计划 | |
| streamplan_single.cpp | 流计划相关函数 | |
| subselect.cpp | 子选择和参数的计划函数 | |
| path | allpaths.cpp | 查找所有可能查询执行路径 |
| clausesel.cpp | 子句选择性计算 | |
| costsize.cpp | 计算关系和路径代价 | |
| pathkeys.cpp | 匹配并建立路径键的公用函数 | |
| pgxcpath_single.cpp | 查找关系和代价的所有可能远程查询路径 | |
| streampath_single.cpp | 并行处理的路径生成 | |
| tidpath.cpp | 确定扫描关系TID(tuple identifier,元组标识符)条件并创建对应TID路径 | |
| equivclass.cpp | 管理等价类 | |
| indxpath.cpp | 确定可使用索引并创建对应路径 | |
| joinpath.cpp | 查找执行一组join操作的所有路径 | |
| joinrels.cpp | 确定需要被连接的关系 | |
| orindxpath.cpp | 查找匹配OR子句集的索引路径 |
4) optimizer主流程
optimizer主流程代码如下:
...
void query_planner(PlannerInfo* root, List* tlist, double tuple_fraction, double limit_tuples,query_pathkeys_callback qp_callback, void *qp_extra, Path** cheapest_path, Path** sorted_path, double* num_groups, List* rollup_groupclauses, List* rollup_lists){
...
if (parse->jointree->fromlist==NIL) {
...
return;
}
setup_simple_rel_arrays(root);
add_base_rels_to_query(root, (Node*)parse->jointree);
check_scan_hint_validity(root);
build_base_rel_tlists(root, tlist);
find_placeholders_in_jointree(root);
joinlist=deconstruct_jointree(root);
reconsider_outer_join_clauses(root);
generate_base_implied_equalities(root);
generate_base_implied_qualities(root);
(*qp_callback) (root, qp_extra);
fix_placeholder_input_needed_levels(root);
joinlist=remove_useless_joins(root, joinlist);
add_placeholders_to_base_rels(root);
total_pages=0;
for (rti=1; rti < (unsigned int)root->simple_rel_array_size; rti++)
{...}
root->total_table_pages=total_pages;
final_rel=make_one_rel(root, joinlist);
final_rel->consider_parallel=consider_parallel;
...
if (parse->groupClause) {...}
else if (parse->hasAggs||root->hasHavingQual||parse->groupingSets)
{...}
else if (parse->distinctClause) {...}
else {...}
cheapestpath=get_cheapest_path(root, final_rel, num_groups, has_groupby);
...
*cheapest_path=cheapestpath;
*sorted_path=sortedpath;
}
PREVIOUS:权威访谈丨政策效果逐渐显现 加快构建房地产发展新模式 NEXT:上海住房公积金网
Categories
焦点新闻
Contact Us
Contact: 焦点-焦点平台-焦点中国加盟站
Phone: 13800000000
Tel: 400-123-4567
E-mail: admin@youweb.com
Add: Here is your company address

